vLLM과 PagedAttention
Research vLLM AI
LLM 서빙 라이브러리
FastAPI 서버를 구축한 뒤, Hugging Face 라이브러리를 사용해서 LLM을 직접 서빙할 수 있지만 성능상 느린 경험을 많이 했다. 이는 Hugging Face 라이브러리가 서빙에 특화되지 않았기 때문이다. 이러한 경험을 통해 막연하게 LLM 서빙은 또 하나의 전문 분야임을 어렴풋이 알 수 있었다.
최근, 외부 LLM을 API 호출로 사용하면 고객 데이터가 유출될 수 있다는 문제가 제기되었다. 따라서 고객 데이터를 사용하는 서비스의 경우, gpt-4.1나 sonnet-4같은 상업용 LLM 대신 사내 GPU 서버에 직접 올린 open-source LLM을 사용하는 방향으로 결정되었다.
현재 우리 회사는 vLLM을 사용해 LLM 서빙을 제공하고 있다. vLLM이 Ollama와 같은 로컬 LLM 서빙 라이브러리 대비 빠른 서빙 속도를 갖는 이유가 궁금해져 vLLM 공식페이지에 있는 논문을 읽고 내용을 정리해보았다.
KV Cache
Transformer 구조에서 하나의 시퀸스에 대해, key-value는 각 토큰이 갖는 고정된 값이므로 매 query마다 다른 토큰의 key-value를 재계산할 필요없다.
따라서, 첫 번째 query에 대한 attention을 계산할 때 시퀸스내의 모든 토큰들의 key-value를 최초로 계산한 뒤에는 메모리에 저장한다. 두 번째 query부터는 key-value 계산없이 메모리에 저장된 key-value를 사용함으로써 빠르게 attention을 계산할 수 있다. 이렇게 메모리에 저장된 key-value를 KV Cache라 한다.
KV Cache는 매 요청(시퀸스)마다 메모리 공간에 할당되고 제거된다. KV Cache 영역은 input prompt token 개수와 generated output token 개수에 비례하기에 각 요청마다 할당받는 사이즈가 다르다.
KV Cache Size 계산 방법
13B OPT 모델 기준으로, 하나의 토큰이 갖는 KV Cache Size는 다음과 같다.
KV Cache Size = 2 × H × L × B = 2 x 5120 x 40 x 2 = 819,200 bytes ~= 800KB
- H = Hidden State Size (5120)
- L = Number of Layers (40)
- B = Bytes per FP16 (2 bytes)
- 2 = Key, Value vectors
해당 모델은 2048 토큰까지 생성할 수 있으므로, 하나의 요청 당
800KB * 2048 ~= 1.6GB
KV Cache Size를 갖게된다.
전통적인 LLM 서빙 방식
LLM decoder와 LLM 서빙
대부분의 LLM 챗모델들은 auto-regressive Transformer (decoder) 이므로, 출력 토큰이 하나하나씩 순차적으로 나온다. 따라서 대부분의 서빙 프레임워크는 하나의 요청에 대해 처리 속도를 높이는 대신 요청을 병렬로 처리하는 방식을 채택하였다. 각 요청마다 고유한 KV Cache 영역을 가지므로 GPU 메모리 관리를 잘해야지 높은 throughput을 가질 수 있다.
배치 처리
모델의 weight는 공유자원이다. 따라서 전통적인 LLM 서빙 프레임워크들은 요청을 배치단위로 묶어 병렬 처리함으로써 서빙 속도를 높였다. 그러나 요청 단위로 배치를 묶기에 두 가지 문제점이 있었다.
- 짧은 output token을 가진 요청이 긴 output token을 가진 요청의 응답 생성이 끝날 때 까지 기달려야 한다.
- 짧은 시퀸스를 가진 요청과 긴 시퀸스를 가진 요청의 사이즈를 맞추기 위해 input, output 패딩이 필요하다. 이는 GPU 메모리 낭비이다.
fine-grained batching mechanism
fine-grained batching mechanism은 요청 단위로 배치를 묶는 대신, iteration 단위로 배치를 묶음으로써 1번 문제를 해결하였다. iteration은 시퀸스에서 하나의 토큰을 생성해내는 작업 단위를 뜻한다.
매 iteration마다, 응답 생성이 완료된 요청들은 배치에서 제거되고, 큐에서 기다리고 있던 새로운 요청이 배치에 추가된다. 이를 통해 짧은 output token을 가진 요청들이 더 이상 기다리지 않고, 비효율적으로 기다리는 요청도 사라지게 되었다.
또한 특별한 GPU 커널에 의해, input output 패딩도 필요없어지게 되며 2번 문제도 해결하였다.
여전히 남아있는 문제점
KV Cache는 매 요청마다 큰 공간을 차지하고, 요청이 끝나면 바로 제거된다. 이러한 과정에서 메모리 공간의 파편화가 발생하여 시간이 지날 수록 메모리 공간을 비효율적으로 사용하게 된다.
기존의 서빙 프레임워크들은 연속된 메모리 공간에 KV Cache를 저장한다. 요청이 들어오면 요청을 처리하는데 필요한 KV Cache 메모리 공간을 미리 할당받아야 하는데, 메모리 공간을 할당받는 시점엔 응답 토큰이 얼마나 생성될 지 모르기에 얼만큼의 공간을 할당 받아야 할지 정확히 알지 못하는 문제가 있다.
따라서 보통 LLM이 생성할 수 있는 최대 길이에 맞춰 최대 크기의 KV Cache 메모리를 할당받는다. 만약 input token과 output token이 모두 짧은 요청이었다면 많은 메모리 공간이 유휴 상태로 놀게된다. 이러한 메모리 비효율성을 internal fragmentation이라 한다.
만약, LLM의 응답 토큰 길이를 정확하게 예측하여 정확히 필요한 크기의 KV Cache 메모리 공간을 할당 받았다 하더라도 external fragmentation이 발생할 수 있다. 각 요청이 할당받는 KV Cache의 메모리 공간이 연속적이고, 크기가 들쭉날쭉하며, 요청이 완료되는 시간이 제각기 다르기 때문이다.

reqA, reqB가 미리 할당받은 메모리 공간은, 실제로는 놀고 있는 슬롯이 존재한다. 이 부분을 internal fragmentation이라 한다.
reqA, reqB 사이에 2개의 슬롯밖에 남지 않아, reqC는 메모리 공간을 할당 받지 못한다. 이렇게 놀고 있는 슬롯을 external fragmentation이라 한다.
vLLM 서빙 방식
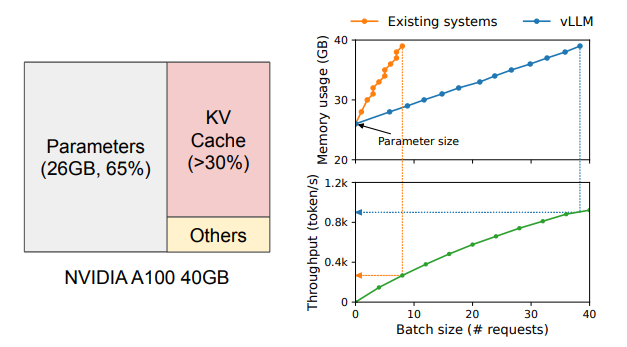 모델이 올라가는 메모리 영역은 static 영역이므로 변하지 않고, 반드시 필요한 부분이다.
모델 활성화에 필요한 메모리 영역은 아주 작고 일시적으로만 필요하다. 따라서 논문의 저자는 매 요청마다 동적으로 변하며, 꽤 많은 메모리 영역을 차지하고 있는 KV Cache 메모리 영역을 효율적으로 바꾸면, 많은 병렬 요청을 처리할 수 있을 것이라 생각했다.
모델이 올라가는 메모리 영역은 static 영역이므로 변하지 않고, 반드시 필요한 부분이다.
모델 활성화에 필요한 메모리 영역은 아주 작고 일시적으로만 필요하다. 따라서 논문의 저자는 매 요청마다 동적으로 변하며, 꽤 많은 메모리 영역을 차지하고 있는 KV Cache 메모리 영역을 효율적으로 바꾸면, 많은 병렬 요청을 처리할 수 있을 것이라 생각했다.
vLLM은 논문 저자가 만든 LLM 서빙 프레임워크로, PagedAttention을 적용하여 KV Cache 메모리 영역을 효율적으로 사용한다. 이로써 같은 VRAM 공간을 사용하더라도 더 많은 요청을 빠르게 처리한다.
PagedAttention
os의 페이징과 가상 메모리에서 아이디어를 얻은 어텐션 알고리즘으로, 각 요청의 KV Cache를 일정 크기의 블록(페이지)으로 나눠 저장한다. KV Cache 블록은 불연속적으로 메모리 공간에 쪼개져 저장되며, 각 KV Cache 블록은 고정된 토큰 개수의 KV Cache로 이루어져 있다.
모든 KV Cache 블록 크기가 동일해지고 KV Cache 블록 저장위치가 블록 슬롯으로 고정됨으로써 external fragmentation이 제거되었다. 또한 전체 KV Cache 메모리 영역을 일정 크기의 KV Cache 블록으로 나눴기에 internal fragmentation 크기를 최소화하였다.
또한 서로 다른 요청들 간, KV Cache 블록 단위로 메모리 공유가 가능해짐으로써 메모리 효율을 더욱 높였다.
각 KV Cache Block의 크기는 적절한 사이즈로 설정해야 한다. 너무 작은 Block 크기는 GPU 사용율을 떨어뜨린다. GPU는 연속된 메모리 공간에 있는 청크를 한번에 읽는 것에 최적화되어 있는데, 작은 KV Cache Block은 KV를 불연속적인 공간에 흩뜨리기 때문이다. 반대로 너무 큰 Block 크기는 internal fragmentation의 증가로 이어진다.
vLLM은 테스트를 통해 KV Cache Block 당 16개의 토큰에 대한 KV를 갖도록 기본 블록 사이즈를 채택하였다. 만약, 현재 필요한 LLM 서빙 환경이 평균적으로 긴 시퀸스를 처리해야 하는 경우라면 블록 사이즈를 이보다 키움으로써 성능 개선을 할 수 있을것이다.
각 KV Cache block에 4개의 토큰에 대한 KV가 저장될 수 있다고 가정할 때, PagedAttention의 응답 생성 과정은 아래와 같다.
가장 기본적인 decoding
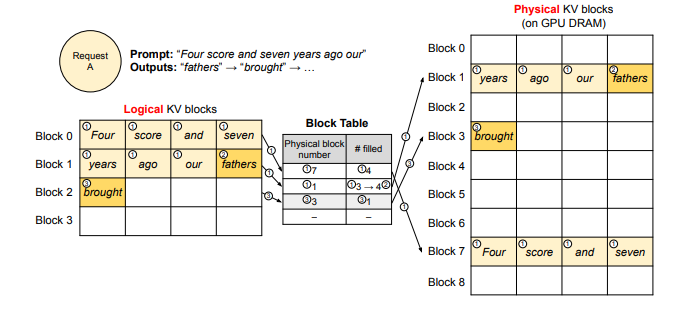
input prompt token: Four, score, and, seven, years, ago, our
generated output token: fathers, brought
각 요청은 자기만의 Logical KV Cache 영역을 가진다.
하나의 input prompt에 대해 하나의 output을 만들어내는 가장 기본적인 응답 생성 방식이다.
요청이 들어왔을때 vLLM의 동작 과정은
- logical block 0에 4개의 토큰이 먼저 들어가고, 나머지 3개의 토큰은 logical block 1에 들어간다.
- KV Cache Manager는 logical block 0, 1을 실제 physical block에 매핑한 후, 블록에 들어있는 KV 개수를 기록한다.
- 응답을 생성하는 단계에선, 생성된 새로운 토큰의 KV값이 logical block에 뒤이어 들어간다.
- 만약 physical block에 토큰이 추가된다면, 기록된 블록에 들어있는 KV 개수 값을 늘린다.
- 요청에 대한 처리가 끝나면, 요청 시 할당된 KV Cache Block 영역을 해제한다.
Parallel Sampling decoding
하나의 input prompt에 대해 다양한 버전의 output을 만들어내는 응답 생성 방식이다. 클라이언트는 원하는 버전의 output을 선택할 수 있다.
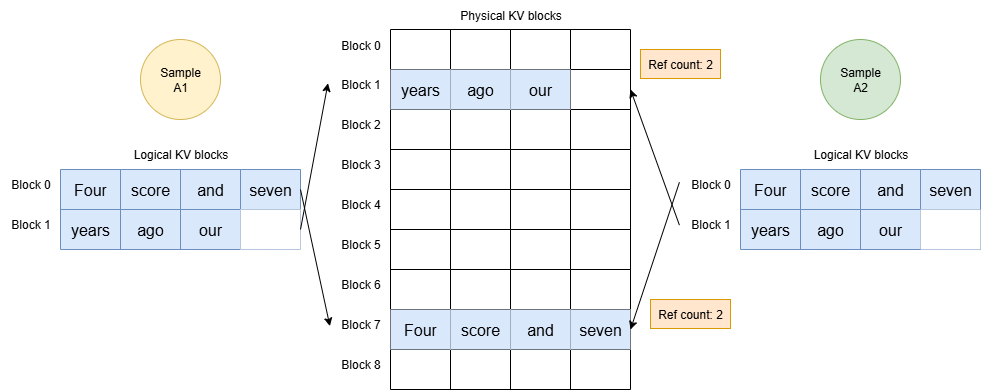 input prompt 토큰의 KV Cache는 Sample A1, A2 모두 공유해서 사용하므로, 효율적이다.
KV Cache Manager는 KV Cache 블록을 참조하는 샘플 개수를 Reference Count로 기록한다.
input prompt 토큰의 KV Cache는 Sample A1, A2 모두 공유해서 사용하므로, 효율적이다.
KV Cache Manager는 KV Cache 블록을 참조하는 샘플 개수를 Reference Count로 기록한다.
- logical block 0에 대응되는 Physical Block 7의 Reference Count = 2
- logical block 1에 대응되는 Physical Block 1의 Reference Count = 2
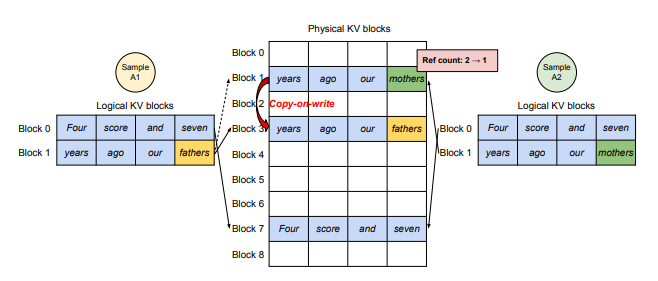 여러 버전의 output token을 추출하는 decoding step에선 상황이 조금 달라진다.
Sample A1은 fathers 토큰 생성, Sample A2는 mothers 토큰 생성을 한다고 가정하자.
output 토큰의 KV값은 logcial block 1 영역에 input prompt 토큰들의 KV 값들에 뒤이어 저장될 것이다. 샘플별로 생성된 output 토큰이 다르기에, logical block 1은 두 샘플이 더이상 공유해서 사용할 수 없다. 따라서 물리적인 메모리 상에 Copy-on-write가 발생하고, Reference count는 감소한다.
여러 버전의 output token을 추출하는 decoding step에선 상황이 조금 달라진다.
Sample A1은 fathers 토큰 생성, Sample A2는 mothers 토큰 생성을 한다고 가정하자.
output 토큰의 KV값은 logcial block 1 영역에 input prompt 토큰들의 KV 값들에 뒤이어 저장될 것이다. 샘플별로 생성된 output 토큰이 다르기에, logical block 1은 두 샘플이 더이상 공유해서 사용할 수 없다. 따라서 물리적인 메모리 상에 Copy-on-write가 발생하고, Reference count는 감소한다.
- logcial block 1의 경우, 각 샘플별로 바라보는 physical block이 달라진다.
- logical block 0의 경우, 각 샘플이 여전히 공유한다.
Scheduling
요청 수가 시스템 capacity를 넘어서면, 스케쥴링이 필요하다. vLLM은 FCFS 스케쥴링을 채택했다. (First Come, First Serve)
output 토큰은 얼마나 길어질 지 알 수 없기에, 많은 요청이 들어오면 GPU 메모리 공간이 바닥나서 더이상 generated output token의 KV를 저장할 공간이 없을 수 있다. 이러한 상황을 해결하기 위해 두 가지를 고려해야 한다.
- 메모리 공간이 바닥났을 때, 어떤 KV Cache Block을 제거해야 할 지
- 메모리 공간의 여유가 생겼을 때, 제거된 KV Cache Block이 다시 필요해질 경우 어떻게 복원할지
제거 전략
Transformer 특성 상, 시퀸스의 모든 토큰에 동시에 접근한다. 따라서 추방시킬 KV Cache 블록을 선정할 필요 없이, 특정 시퀸스의 모든 KV Cache를 제거하거나, 하나도 제거하지 않는 정책을 사용한다. (all-or-nothing eviction policy)
제거대상이 되는 요청(시퀸스)은 FCFS 스케쥴링에 의거하여, 가장 나중에 들어온 시퀸스가 선정된다.
복원 전략
크게 2가지 방법으로 나뉜다.
-
Swapping
OS에서 전통적으로 사용하는 방법이다. OS에서는 evicted page를 디스크의 Swap Space로 추방시킨다. vLLM은 이와 비슷하게 evicted KV Cache Block을 CPU 메모리로 추방시킨다. 이 경우, vLLM은 CPU 메모리로 추방된 시퀸스들이 모두 GPU 메모리로 돌아와 처리되기 전까지 새로운 요청을 받지 않는다. 요청이 끝나 GPU에 가용 메모리 공간이 생기면 CPU 공간에 위치한 시퀸스들을 GPU 메모리로 가져와 처리한다. -
Recomputation
시퀸스의 KV를 다시 계산하여 캐싱하는 전략이다. 이전에 생성된 input token과 output token을 하나로 합쳐 KV를 계산함으로써 한 iteration에서 추방된 시퀸스의 KV Cache를 재생성한다.
기본적으로 Swapping과 Recomputation 성능에 영향을 주는 변수는 CPU RAM과 GPU 메모리 간 Bandwidth, GPU 연산 성능이다. 일반적으로 Swapping은 KV Cache Block 사이즈가 클 때 유리하다. 반면 Recomputation은 KV Cache Block을 버려버리므로, KV Cache Block의 사이즈와 상관없이 일정한 시간이 소요된다. 따라서 KV Cache Block 사이즈가 작을 때 유리하다.
결론
decoder 구조 특성 상, LLM 응답은 순차적으로 생성된다. 따라서 하나의 요청을 처리하는데 걸리는 속도가 느리다. 따라서 대부분의 LLM 서빙 프레임워크는 병렬 처리를 통해 throughput을 높인다. 하지만 각 요청당 KV Cache를 저장하기 위한 메모리 공간의 한계가 있어 병렬 처리 가능한 요청 개수를 늘리는 데엔 한계가 있었다.
GPU 연산속도는 새로운 세대가 나올때마다 2배씩 빨라지지만, GPU 메모리는 아직도 최대 80GB에 머물러 있다. vLLM은 서빙 성능은 GPU memory bound이고, GPU 메모리 크기가 bottle neck임을 증명하고 개선하였다.
출처
Efficient Memory Management for Large Language Model Serving