사내 LLM이 혼자 10분째 주절대는 건에 대하여 - SSE 타임아웃 트러블슈팅
Engineering LangChain Python
문제 상황
사내 GPU에서 vllm으로 호스팅하는 LLM들이 있다. 현재 Qwen3-30B-A3B-Instruct 모델을 주력으로 사용 중이고, 해당 모델을 호출하기 위해 langchain에서 제공하는 ChatOpenAI 클래스를 사용하고 있다.
이 모델은 간헐적으로 모델이 허용하는 max-length에 다다를 때까지 긴 시간 동안 응답을 생성하는 이슈가 있다. 이는 정상적인 응답을 만들어내는 상황이 아니기에 사용 가치가 없는 응답이고, ERP 서버에 의해 타임아웃 처리되어 클라이언트는 응답을 기다리는 대신 5xx 에러를 받게 된다.
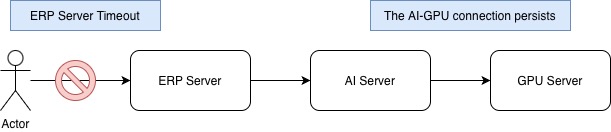
문제는 AI 서버와 GPU 서버 간의 관계에서는, ERP 서버가 클라이언트 요청을 끊는 것과 상관없이 계속해서 연결 상태를 유지한다. GPU 서버는 계속해서 무의미한 응답을 생성하고, AI 서버는 이를 계속해서 받는다.
이렇게 특정 request에 대한 응답 생성이 오랜 시간 이루어지면, GPU 서버의 GPU와 CPU 자원을 불필요하게 오랜 시간 점유하는 상황이 발생한다. 따라서 AI 서버에서 GPU 서버에 LLM 응답을 요청한 경우에 너무 긴 시간 동안 무의미한 응답을 생성하지 않도록 타임아웃이 필요하다.
def create_qwen3_30b_a3b_instruct_2507_fp8_chat_model():
connection = Runtime.get("connection", Connection)
return ChatOpenAI(
model="Qwen/Qwen3-30B-A3B-Instruct-2507-FP8",
base_url=f"{connection.llm_qwen_protocol}://{connection.llm_qwen_host}:{connection.llm_qwen_port}/v1",
timeout=45
)
ChatOpenAI는 애플리케이션 수준에서 타임아웃을 관리한다. 내부적으로 각 소켓 read/write 작업은 Task에 할당되어 개별적으로 타임아웃이 적용되며, Task 작업 시간이 타임아웃 시간을 초과하는 경우 이벤트 루프가 현재 Task에 CancelledError를 주입하여 작업을 중지시킨다.
따라서, timeout 옵션을 ChatOpenAI 클래스 생성자에 넣어주면, LLM 응답 전체를 한번에 받는 일반적인 HTTP 트랜잭션 상황에선 타임아웃이 잘 동작한다. ainvoke, invoke 호출을 예로 들 수 있다.
반면, 청크 단위로 응답하는 SSE 상황에선 긴 시간동안 하나의 전체응답을 만드는 대신, 소켓을 통해 데이터를 청크 단위로 단시간에 지속해서 준다. 하나의 청크의 응답시간이 타임아웃 시간을 초과하는 경우엔 타임아웃이 발생하지만, 전체 응답 시간에 대한 타임아웃으로는 동작하지 않는다.
정리하면, SSE 응답이 엄청 길어져도 전체 응답 시간에 대해 timeout 옵션이 의도대로 동작되지 않는다.
ChatVllm 클래스 만들기
streaming 상황에서도 SSE 커넥션을 타임아웃 시간까지만 기다려준 후 끊어버리도록 동작시키기 위해서 ChatOpenAI를 상속받는 subclass를 생성하였다.
ChatModel을 생성할 때만 타임아웃을 적용함으로써, 노드단이나 비즈니스 로직에선 타임아웃 처리에 대해 신경쓰지 않아도 되도록 하고 싶었다.
class ChatVllm(ChatOpenAI):
stream_timeout: float | None = None
def __init__(self, *args, **kwargs):
if "api_key" not in kwargs:
kwargs["api_key"] = SecretStr("vllm-only-base-model")
super().__init__(*args, **kwargs)
self.stream_timeout = kwargs.get("timeout", None)
async def _astream( # TODO: timeout 로직 적용!
self, *args: Any, **kwargs: Any
) -> AsyncIterator[ChatGenerationChunk]:
async for chunk in super()._astream(*args, **kwargs):
yield chunk
chat_vllm.py
ChatModel 인터페이스에서 SSE 작업을 수행하는 메서드는 astream이고, astream은 내부적으로 _astream을 호출한다. 따라서 _asteram 메서드를 오버라이드하여 타임아웃 로직을 적용하기로 결정했다.
asyncio.timeout 적용
asyncio.timeout(delay) 는 특정 작업 완료 시간을 제한하는 비동기 컨텍스트 매니저를 반환하는 built-in function 이다. 쉽게 말해 async 블록 내의 작업이 인자로 넘어간 타임아웃 시간을 넘으면 현재 작업을 중지 시킨 뒤 asyncio.CancelledError를 발생시키고, 이를 TimeoutError로 변환시켜 raise한다.
async def _astream(
self, *args: Any, **kwargs: Any
) -> AsyncIterator[ChatGenerationChunk]:
async with asyncio.timeout(self.stream_timeout):
async for chunk in super()._astream(*args, **kwargs):
yield chunk
chat_vllm.py
ChatVllm 생성 시 설정한 타임아웃 시간만큼 내부 작업 완료를 기다리도록 구현하였다.
model = ChatVllm(
model="Qwen/Qwen3-30B-A3B-Instruct-2507-FP8",
base_url=f"{connection.llm_qwen_protocol}://{connection.llm_qwen_host}:{connection.llm_qwen_port}/v1",
extra_body={"ignore_eos": True},
timeout=45
)
async for chunk in model.astream(text):
print(chunk.content)
async for chunk in self._astream(
File "***\test.py", line 27, in _astream
async with asyncio.timeout(self.stream_timeout):
File "***\Python\Python311\Lib\asyncio\timeouts.py", line 111, in __aexit__
raise TimeoutError from exc_val
TimeoutError
ChatModel을 생성한 후 astream을 호출해보면, timeout으로 넘겨준 시간이 지난 경우 클라이언트 단(AI 서버)에서 타임아웃을 발생시켜 SSE 연결을 끊는다. GPU 서버는 더이상 응답을 생성하지 않고, GPU 자원과 CPU 자원을 반환한다.
LangChain Runnable에서 asyncio.timeout이 동작하지 않는 문제 발생
실제 비즈니스 로직에선 ChatModel의 astream을 호출하지 않는다. 기본적으로 프롬프트 템플릿과 ChatModel을 하나로 연결하여 LangChain에서 제공하는 Runnable로 만든 후 astream을 호출한다.
chain = self._prompt | model
async for chunk in chain.astream(
{
CONTEXT: join_documents(documents),
QUESTION: question,
HISTORY: history,
},
):
# ...
chain = Runnable
그런데 문제는, 이 경우엔 응답 생성이 아무리 길어지더라도 타임아웃이 발생하지 않는다. 즉, ChatModel 인터페이스의 astream을 사용할 때와 LangChain Runnable 인터페이스의 astream을 사용할 때의 내부 동작이 달라 asyncio.timeout이 동작하지 않음을 짐작할 수 있다.
asyncio.timeout과 Timeout 인스턴스 내부 동작방식
def timeout(delay: Optional[float]) -> Timeout:
"""Timeout async context manager.
Useful in cases when you want to apply timeout logic around block
of code or in cases when asyncio.wait_for is not suitable. For example:
>>> async with asyncio.timeout(10): # 10 seconds timeout
... await long_running_task()
delay - value in seconds or None to disable timeout logic
long_running_task() is interrupted by raising asyncio.CancelledError,
the top-most affected timeout() context manager converts CancelledError
into TimeoutError.
"""
loop = events.get_running_loop()
return Timeout(loop.time() + delay if delay is not None else None)
asyncio.timeoutbuilt-in function
timeout 함수를 호출하면, 현재 이벤트 루프의 시간에 파라미터로 넣어준 타임아웃 시간을 더해 Timeout 인스턴스를 생성 후 반환한다.
@final
class Timeout:
"""Asynchronous context manager for cancelling overdue coroutines.
Use `timeout()` or `timeout_at()` rather than instantiating this class directly.
"""
def __init__(self, when: Optional[float]) -> None:
"""Schedule a timeout that will trigger at a given loop time.
- If `when` is `None`, the timeout will never trigger.
- If `when < loop.time()`, the timeout will trigger on the next
iteration of the event loop.
"""
self._state = _State.CREATED
self._timeout_handler: Optional[events.TimerHandle] = None
self._task: Optional[tasks.Task] = None
self._when = when
# ...
def reschedule(self, when: Optional[float]) -> None:
"""Reschedule the timeout."""
assert self._state is not _State.CREATED
if self._state is not _State.ENTERED:
raise RuntimeError(
f"Cannot change state of {self._state.value} Timeout",
)
self._when = when
if self._timeout_handler is not None:
self._timeout_handler.cancel()
if when is None:
self._timeout_handler = None
else:
loop = events.get_running_loop()
if when <= loop.time():
self._timeout_handler = loop.call_soon(self._on_timeout)
else:
self._timeout_handler = loop.call_at(when, self._on_timeout)
async def __aenter__(self) -> "Timeout":
self._state = _State.ENTERED
self._task = tasks.current_task()
self._cancelling = self._task.cancelling()
if self._task is None:
raise RuntimeError("Timeout should be used inside a task")
self.reschedule(self._when)
return self
async def __aexit__(
self,
exc_type: Optional[Type[BaseException]],
exc_val: Optional[BaseException],
exc_tb: Optional[TracebackType],
) -> Optional[bool]:
assert self._state in (_State.ENTERED, _State.EXPIRING)
if self._timeout_handler is not None:
self._timeout_handler.cancel()
self._timeout_handler = None
if self._state is _State.EXPIRING:
self._state = _State.EXPIRED
if self._task.uncancel() <= self._cancelling and exc_type is exceptions.CancelledError:
# Since there are no new cancel requests, we're
# handling this.
raise TimeoutError from exc_val
elif self._state is _State.ENTERED:
self._state = _State.EXITED
return None
def _on_timeout(self) -> None:
assert self._state is _State.ENTERED
self._task.cancel()
self._state = _State.EXPIRING
# drop the reference early
self._timeout_handler = None
Timeoutclass
async with asyncio.timeout(self.stream_timeout): # __aenter__ 호출
async for chunk in super()._astream(*args, **kwargs): # 내부 task 수행
yield chunk
# async with block을 나갈 때 __aexit__ 호출
Timeout 클래스는 __aenter__와 __aexit__을 구현한 비동기 컨텍스트 매니저로 위와 같은 흐름으로 동작한다.
내부 로직을 살펴보면, async with block 진입 시, self._task를 현재 실행중인 task로 할당한다. 이후 reschedule 메서드를 호출하여 컨텍스트 내의 작업 시간이 타임아웃 시간을 넘었는 지 검사한다. 만약 타임아웃 시간을 넘었다면 이벤트 루프가 다음 작업으로 _on_timeout 메서드를 호출하도록 한다.
_on_timeout 메서드에선, 미리 할당한 self._task 작업 진행을 취소하고 self._state를 EXPIRING으로 바꾼다. 현재 진행중이던 작업을 취소하였기에 exceptions.CancelledError가 발생하고, async with block에서 바로 나가게 된다. 이때 __aexit__ 을 호출하면서 CancelledError를 TimeoutError로 감싸 raise한다.
ChatModel 인터페이스의 astream 호출
ChatModel 인터페이스는 astream 호출 시에, Task-1 하나가 LLM이 생성한 응답 청크를 반환하는 데 관여한다.
즉, Task-1이 async generator를 직접 모두 순회한다. 따라서 작업시간이 타임아웃 시간을 초과하면 async generator 순회 작업을 바로 중지한다. 다시 말해, SSE 상황에서의 타임아웃이 전체 응답 생성 시간에 적용되길 바라는 원래 의도대로 잘 동작한다.
<Task pending name='Task-1' coro=<main() running at ***\test.py:22> cb=[_run_until_complete_cb() at ***\Python\Python311\Lib\asyncio\base_events.py:181]>
Timeout인스턴스의self._task
Runnable 인터페이스의 astream 호출
LangChain에서 chain으로 일컫는 Runnable 인터페이스는 astream 호출 시, 각 응답 청크마다 각각의 Task를 생성 후 할당한다.
class Runnable(ABC, Generic[Input, Output]):
# ...
async def _atransform_stream_with_config(
self,
inputs: AsyncIterator[Input],
transformer: Callable[[AsyncIterator[Input]], AsyncIterator[Output]]
| Callable[
[AsyncIterator[Input], AsyncCallbackManagerForChainRun],
AsyncIterator[Output],
]
| Callable[
[AsyncIterator[Input], AsyncCallbackManagerForChainRun, RunnableConfig],
AsyncIterator[Output],
],
config: RunnableConfig | None,
run_type: str | None = None,
**kwargs: Any | None,
) -> AsyncIterator[Output]:
"""Transform a stream with config.
Helper method to transform an Async `Iterator` of `Input` values into an
Async `Iterator` of `Output` values, with callbacks.
Use this to implement `astream` or `atransform` in `Runnable` subclasses.
"""
# ...
try:
while True:
chunk = await coro_with_context(anext(iterator), context) # 각 청크를 처리하는 task를 매번 생성한다.
yield chunk
if final_output_supported:
if final_output is None:
final_output = chunk
else:
try:
final_output = final_output + chunk
except TypeError:
final_output = chunk
final_output_supported = False
else:
final_output = chunk
except StopAsyncIteration:
pass
# ...
base.py
이는, Timeout 인스턴스에 할당 된 self._task는 전체 응답 청크들 중 첫 번째 응답 청크만을 기다리는 Task로 할당됨을 의미한다.
<Task pending name='Task-2' coro=<<async_generator_asend without __name__>()> cb=[Task.task_wakeup()]>
Timeout인스턴스의self._task
다시 말하면, 첫 응답 청크를 기다리는 Task-2가 완료되기 전에 타임아웃이 발생하면 _on_timeout에서 self._task.cancel()은 현재 실행중인 Task-2의 작업을 정확히 중지시키고, exceptions.CancelledError 역시 정확하게 발생시킨다. 따라서 TimeoutError를 성공적으로 발생시킨다.
하지만, 일반적으로는 각 청크는 빠른 시간 내에 오기 때문에 self._task가 가리키는 Task-2는 금새 작업을 완료하고 타임아웃이 발생할 시점에 실행중인 작업은 Task-N이다. Task가 계속해서 바뀌니 Timeout 인스턴스는 현재 작업 중인 정확한 Task를 종료시킬 수 없다. 결국 GPU 서버의 LLM은 타임아웃 시간이 지났음에도 계속해서 응답 청크를 생성하고, GPU 자원과 CPU 자원을 점유한다.
각 Task가 현재까지의 응답 생성 시간을 계산하도록 메서드 변경
class ChatVllm(ChatOpenAI):
stream_timeout: float | None = None
def __init__(self, *args, **kwargs):
if "api_key" not in kwargs:
kwargs["api_key"] = SecretStr("vllm-only-base-model")
super().__init__(*args, **kwargs)
self.stream_timeout = kwargs.get("timeout", None)
async def _astream(
self, *args: Any, **kwargs: Any
) -> AsyncIterator[ChatGenerationChunk]:
if self.stream_timeout is None:
async for chunk in super()._astream(*args, **kwargs):
yield chunk
else:
start_time = time.monotonic()
async for chunk in super()._astream(*args, **kwargs):
elapsed = time.monotonic() - start_time
if elapsed > self.stream_timeout:
raise asyncio.TimeoutError(
f"Stream timeout after {elapsed:.2f} seconds"
)
yield chunk
chat_vllm.py
각 Task가 매번 작업 시간을 계산함으로써 타임아웃을 구현하였다. 각 Task는 _astream async generator의 프레임에 보존된 start_time을 참조하여 지금까지 응답 생성에 걸린 시간을 매 청크마다 계산한다. 만약 Task-N에서 N번째 응답을 생성할 때까지 걸린 시간이 타임아웃 시간을 넘어서면 더 이상 응답을 생성하지 않고 TimeoutError를 발생시킨다.
정확히 현재 실행 중인 Task-N에서 에러가 발생하므로, Runnable의 _atransform_stream_with_config 루프에서의 Task 생성이 중지되고 결과적으로 GPU 서버 LLM의 응답 생성을 중지시킨다.
버전정보
- python 3.11.4
- langchain 1.0.8
- langchain-openai 0.3.34