vLLM and PagedAttention
Research vLLM AI
LLM Serving Libraries
After building a FastAPI server and serving LLMs directly using the Hugging Face library, I often experienced poor performance. This is because the Hugging Face library is not specialized for serving. Through these experiences, I vaguely realized that LLM serving itself is another specialized field.
Recently, concerns have been raised that using external LLMs through API calls may lead to customer data leakage. Therefore, for services that use customer data, we decided to run open-source LLMs directly on our in-house GPU servers instead of relying on commercial LLMs like gpt-4.1 or sonnet-4.
Currently, our company provides LLM serving using vLLM. I became curious why vLLM offers faster serving speeds compared to local LLM serving libraries such as Ollama, so I read the paper on the vLLM official page and summarized the contents.
KV Cache
In a Transformer architecture, for a given sequence, the key-value pairs are fixed values for each token. Therefore, there is no need to recalculate the key-value pairs of other tokens for every query.
When calculating attention for the first query, the key-value pairs of all tokens in the sequence are computed once and stored in memory. From the second query onward, attention can be computed quickly by reusing the stored key-value paris without recomputation. This stored set of key-value pairs is called the KV Cache.
The KV Cache is allocated and freed in memory for each request(sequence). It size depends on the number of input prompt tokens and generated output tokens, so the memory allocated per request varies.
How to Calculate KV Cache Size
For the 13B OPT model, the KV Cache size for a single token is:
KV Cache Size = 2 × H × L × B
= 2 × 5120 × 40 × 2
= 819,200 bytes ≈ 800 KB
- H = Hidden State Size (5120)
- L = Number of Layers (40)
- B = Bytes per FP16 (2 bytes)
- 2 = Key, Value vectors
Since this model can generate up to 2048 tokens, the KV Cache size per request becomes:
800KB * 2048 ~= 1.6GB
Traditional LLM Serving Approach
LLM Decoder and Serving
Most LLM chat models are auto-regressive Transformers (decoders), meaning output tokens are generated one by one in sequence. Therefore, most serving frameworks have adopted parallel request processing rather than speeding up a single request. Since each request has its own KV Cache region, careful GPU memory management is essential to achieve high throughput.
Batch Processing
Model weights are shared resources. Thus, traditional serving frameworks improved throughput by grouping requests into batches for parallel processing. Howerver, batching by request introduced two problems:
- Requests with short output tokens had to wait until requests with long output tokens finished.
- To align short and long sequences, input/output padding was required, which wasted GPU memory.
Fine-Grained Batching Mechanism
The fine-grained batching mechanism solves the first problem by grouping not at the request level, but at the iteration level. An iteration refers to the operation of generating a single token in the sequence.
At each iteration:
- Requests that have completed response generation are removed from the batch.
- New requests waiting in the queue are added to the batch.
This allows short-output requests to finish immediately, elimination inefficient waiting.
Furthermore, with specialized GPU kernels, input/output padding is no longer required, resolving the second problem as well.
Remaining Problems
The KV Cache consumes a large memory space for each request and is freed when the request ends. This process leads to memory fragmentation, which makes memory usage inefficient over time.
Traditional serving frameworks store KV Cache in contiguous memory blocks. When a request arrivers, they must pre-allocate KV Cache memory required to process it. However, at allocation time, the number of output tokens is unknown, so it is impossible to know exactly how much memory to reserve.
As a result, frameworks usually allocate KV Cache memory based on the maximum sequence length supported by the LLM. If both the input tokens and output tokens are short, much of this memory remains idle. This inefficiency is called internal fragmentation.
Even if the output length of the LLM could be predicted and the exact amount of KV Cache memory allocated, external fragmentation may still occur. This is because the memory blocks for each requests must be contiguous, their sizes vary, and the requests complete at different times.

The unused slots in reqA and reqB’s pre-allocated memory are internal fragmentation.
Since only 2 slots remain between reqA and reqB, reqC cannot be allocated even though free slots exist elsewhere. This is external fragmentation.
vLLM Serving Approach
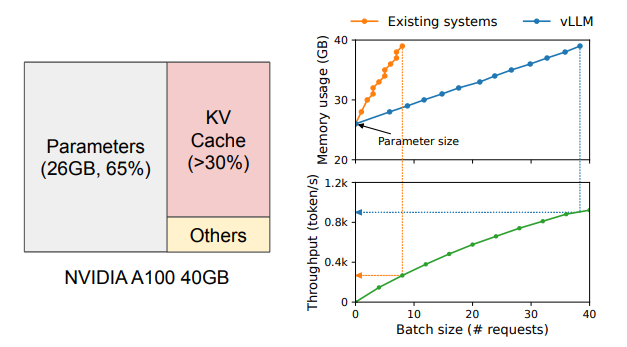
The memory region used to load the model is static-it does not change and is always required. The memory needed to activate the model is small and only required temporarily.
The authors of the paper noted that the KV Cache memory region, which is dynamically allocated for every request and consumes a large amount of memory, could be optimized. If this region were managed more efficiently, it would be possible to handle far more parallel requests.
vLLM is the serving framework proposed by authors. By applying PagedAttention, it uses KV Cache memory far more efficiently, allowing more requests to be processed faster within the same VRAM space.
PagedAttention
PagedAttention is an attention algorithm inspired by OS paging and virtual memory. It splits each request’s KV Cache into fixed-size blocks (pages). These KV Cache blocks are stored discontinuously in memory, and each block contains the KV Cache for a fixed number of tokens.
Since all KV Cache blocks are of the same size and stored in fixed block slots, external fragmentation is eliminated. In addition, by dividing the entire KV Cache memory region into fixed-size blocks, the amount of internal fragmentation is minimized.
Moreover, KV Cache blocks can be shared across different requests, further improving memory efficiency.
The size of each KV Cache block must be set appropriately. If the block size is too small, GPU utilization decreases. This is because GPUs are optimized to read contiguous memory chunks at once, but small KV Cache Blocks scatter KV across non-contiguous memory spaces. Conversely, if the block size is too large, it leads to an increase in internal fragmentation.
Through testing, vLLM adopted a default block size where each KV Cache Block holds KV for 16 tokens. If the current LLM serving environment typically processes long sequences, increasing the block size beyond this can improve performance.
Assuming each KV Cache Block can store KV for 4 tokens, the response generation process of PagedAttention is as follows.
Basic Decoding
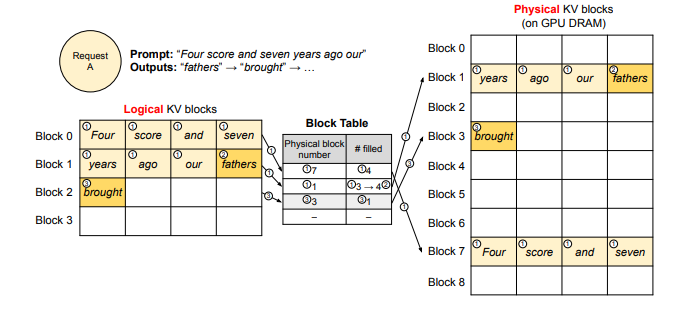
input prompt token: Four, score, and, seven, years, ago, our
generated output token: fathers, brought
Each request has its own Logical KV Cache region.
This is the most basic response generation method, where one input prompt produces one output.
When a request arrives, vLLM works as follows:
- The first 4 tokens are placed into logical block 0, and the remaining 3 tokens go into logical block 1.
- The KV Cache Manager maps logical blocks 0 and 1 to physical blocks and records the number of KV entries in each block.
- During the response generation step, the KV values of newly generated tokens are appended to the logical blocks.
- If tokens are added to a physical block, the recorded KV entry count for that block is incremented.
- When the request is completed, the KV Cache blocks allocated to it are released.
Parallel Sampling Decoding
This is a response generation method where multiple versions of output are produced from the same input prompt. The client can then choose the preferred output version.
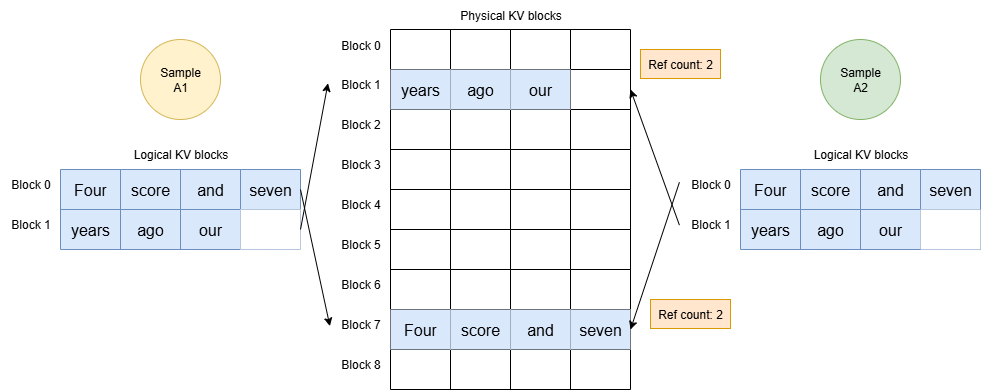 The KV Cache of the input prompt tokens is shared across Sample A1 and A2, making it efficient. The KV Cache Manager records the number of samples referencing a KV Cache block as a Reference Count.
The KV Cache of the input prompt tokens is shared across Sample A1 and A2, making it efficient. The KV Cache Manager records the number of samples referencing a KV Cache block as a Reference Count.
- Physical Block 7 corresponding to Logical Block 0 -> Reference Count = 2
- Physical Block 1 corresponding to Logical Block 1 -> Reference Count = 2
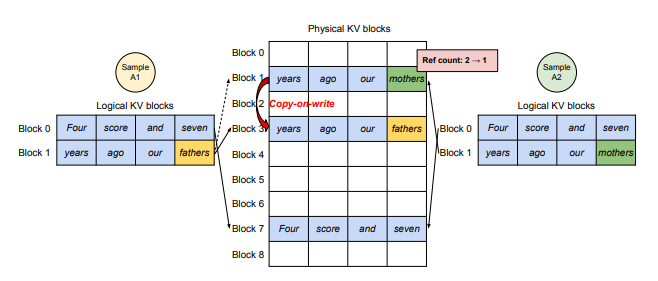 During the decoding step, when different versions of output tokens are generated, the situation changes. Suppose Sample A1 generates the token
During the decoding step, when different versions of output tokens are generated, the situation changes. Suppose Sample A1 generates the token fathers while Sample A2 generates mothers. The KV values of theses output tokens will be stored after the input prompt tokens’ KV values in logical block 1. Since the generated output tokens differ between samples, logical block 1 can no longer be shared. Thus. copy-on-write occurs in physical memory, and the reference count decreases.
- For logical block 1, each sample now points to a different physical block.
- For logical block 0, the samples still share the same block.
Scheduling
When the number of requests exceeds system capacity, scheduling becomes necessary. vLLM adopts FCFS (First Come, First Serve) scheduling.
Since the length of output tokens cannot be known in advance, if many requests arrive, GPU memory may run out and there may be no space left to store KV for additional generated output tokens. To address this situation, two considerations are required:
- Which KV Cache Blocks to evict when memory runs out
- How to restore evicted KV Cache Blocks if they are needed again once memory becomes available
Eviction Policy
Due to the Transformer’s nature, all tokens in a sequence are accessed in simultaneously. Therefore, instead of selecting specific KV Cache Blocks for eviction, vLLM uses an all-or-nothing eviction policy: either all KV Cache of a sequence are evicted or none are.
The sequence chosen for eviction is the most recently arrived one, according to FCFS scheduling.
Restoration Policy
There are two main strategies:
-
Swapping A traditional OS method. In OS, evicted pages are swapped out to disk. Similarly. vLLM swaps evicted KV Cache Blocks to CPU memory. In this case, vLLM does not accept new requests until all sequences swapped to CPU memory are brought back to GPU memory and processed.
-
Recomputation Recomputes and re-caches the KV of a sequence. By combining previously generated input tokens and output tokens, the KV Cache for the evicted sequence is regenerated in a single iteration.
The performance of Swapping and Recomputation primarily depends on the bandwidth between CPU RAM and GPU memory as well as GPU compute performance. Swapping is advantageous when the KV Cache Block size is large. Recomputation discards KV Cache Blocks and requires a fixed amount of time regardless of block size. Therefore, it is advantageous when KV Cache Blocks are small.
Conclusion
Due to the nature of the decoder architecture, LLM responses are generated sequentially, which makes processing a single request slow. Therefore, most LLM serving frameworks increase throughput through parallel processing. Howerver, because each request requires memory space to store its KV Cache, there has been a limit to how many requests can be processed in parallel.
While GPU compute speed doubles with each new generation, GPU memory capacity still remains at around 80 GB. vLLM demonstrated that serving performance is GPU memory bound and that GPU memory size is the bottleneck - and it introduced improvements to overcome this limitation.
References
Efficient Memory Management for Large Language Model Serving