That Time Our In-House LLM Kept Babbling for 10 Minutes Straight| An SSE Timeout Troubleshooting Story
Engineering LangChain Python
Issue
There are LLMs hosted via vLLM on internal company GPUs. Currently, the Qwen3-30B-A3B-Instruct model is primarily used, and the ChatOpenAI class provided by LangChain is utilized to call this model.
There is an issue where this model intermittently generates responses for an extended period until it reaches the max-length allowed by the model. Since these are not normal responses, they have no practical value, and the ERP server already timed out, clents are met with 5xx errors instead of the expected response.
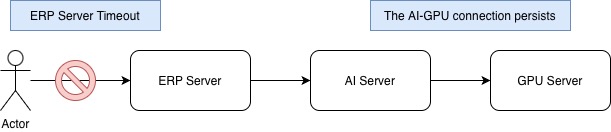
The problem is that in the relationship between the AI server and the GPU server, the connection remains active regardless of the ERP server disconnecting the client request. The GPU server continues to generate meaningless responses, and the AI server continues to receive them.
When response generation for a specific request persists for such a long time, it leads to a situation where the GPU and CPU resources of the GPU server are unnecessarily occupied. Therefore, a timeout is required when the AI server requests an LLM response from the GPU server to prevent the generation of meaningless responses for an excessively long duration.
def create_qwen3_30b_a3b_instruct_2507_fp8_chat_model():
connection = Runtime.get("connection", Connection)
return ChatOpenAI(
model="Qwen/Qwen3-30B-A3B-Instruct-2507-FP8",
base_url=f"{connection.llm_qwen_protocol}://{connection.llm_qwen_host}:{connection.llm_qwen_port}/v1",
timeout=45
)
ChatOpenAI manages timeouts at the application level. Internally, each socket read/write operation is assigned to a Task with individual timeouts applied. If a Task’s execution time exceeds the timeout duration, the event loop injects a CancelledError into the current Task to stop the operation.
Therefore, providing the timeout option to the ChatOpenAI class constructor works correctly in typical HTTP transaction scenarios where the entire LLM response is received at once, such as with ainvoke or invoke calls.
In contrast, in SSE (Server-Sent Events) scenarios where responses are delivered in chunks, the server continuously sends data chunks over the socket in short intervals rather than producing one complete response over a long period. A timeout occurs if the response time for a single chunk exceeds the timeout limit, but it does not function as a timeout for the total response time.
In summary, even if an SSE response becomes extremely long, the timeout option does not work as intended for the overall response duration.
Creating the ChatVllm Class
I created a subclass inheriting from ChatOpenAI to ensure that even in streaming scenarios, the SSE connection is terminated after exhausting the total response time, waiting only until the timeout period.
By applying the timeout directly when creating the ChatModel, I wanted to ensure that the node level or business logic does not need to handle timeout processing.
class ChatVllm(ChatOpenAI):
stream_timeout: float | None = None
def __init__(self, *args, **kwargs):
if "api_key" not in kwargs:
kwargs["api_key"] = SecretStr("vllm-only-base-model")
super().__init__(*args, **kwargs)
self.stream_timeout = kwargs.get("timeout", None)
async def _astream( # TODO: apply timeout logic
self, *args: Any, **kwargs: Any
) -> AsyncIterator[ChatGenerationChunk]:
async for chunk in super()._astream(*args, **kwargs):
yield chunk
chat_vllm.py
In the ChatModel interface, the method responsible for performing SSE operations is astream, which internally calls _astream. Therefore, I decided to override the _astream method to implement the timeout logic.
Applying asyncio.timeout
asyncio.timeout(delay) is a built-in function that returns an asynchronous context manager to limit the completion time of a specific task. Simply put, if the task within the async block exceeds the timeout duration passed as an argument, it stops the current task, injects an asyncio.CancelledError, and then converts and raises it as a TimeoutError.
async def _astream(
self, *args: Any, **kwargs: Any
) -> AsyncIterator[ChatGenerationChunk]:
async with asyncio.timeout(self.stream_timeout):
async for chunk in super()._astream(*args, **kwargs):
yield chunk
chat_vllm.py
I implemented it to wait for internal task completion for the duration of the timeout set during the creation of the ChatVllm instance.
model = ChatVllm(
model="Qwen/Qwen3-30B-A3B-Instruct-2507-FP8",
base_url=f"{connection.llm_qwen_protocol}://{connection.llm_qwen_host}:{connection.llm_qwen_port}/v1",
extra_body={"ignore_eos": True},
timeout=45
)
async for chunk in model.astream(text):
print(chunk.content)
async for chunk in self._astream(
File "***\test.py", line 27, in _astream
async with asyncio.timeout(self.stream_timeout):
File "***\Python\Python311\Lib\asyncio\timeouts.py", line 111, in __aexit__
raise TimeoutError from exc_val
TimeoutError
After creating the ChatModel and calling astream, if the time passed to timeout is exceeded, the client side (AI server) triggers a timeout and terminates the SSE connection. The GPU server then stops generating responses and releases both GPU and CPU resources.
Issue with asyncio.timeout in LangChain Runnables
In actual business logic, the astream method of the ChatModel is not called directly. Instead, a PromptTemplate and the ChatModel are typically linked together into a LangChain Runnable, and the astream method is then called on this combined object.
chain = self._prompt | model
async for chunk in chain.astream(
{
CONTEXT: join_documents(documents),
QUESTION: question,
HISTORY: history,
},
):
# ...
chain = Runnable
However, the problem is that in this case, a timeout does not occur no matter how long the total response generation takes. This suggests that the internal behavior of the astream method in the ChatModel interface differs from that of the LangChain Runnable interface, causing asyncio.timeout to fail to operate as expected.
Internal Workings of asyncio.timeout and Timeout Instance
def timeout(delay: Optional[float]) -> Timeout:
"""Timeout async context manager.
Useful in cases when you want to apply timeout logic around block
of code or in cases when asyncio.wait_for is not suitable. For example:
>>> async with asyncio.timeout(10): # 10 seconds timeout
... await long_running_task()
delay - value in seconds or None to disable timeout logic
long_running_task() is interrupted by raising asyncio.CancelledError,
the top-most affected timeout() context manager converts CancelledError
into TimeoutError.
"""
loop = events.get_running_loop()
return Timeout(loop.time() + delay if delay is not None else None)
asyncio.timeoutbuilt-in function
When the timeout function is called, it calculates a deadline by adding the provided timeout argument to the current event loop time, then creates and returns a Timeout instance.
@final
class Timeout:
"""Asynchronous context manager for cancelling overdue coroutines.
Use `timeout()` or `timeout_at()` rather than instantiating this class directly.
"""
def __init__(self, when: Optional[float]) -> None:
"""Schedule a timeout that will trigger at a given loop time.
- If `when` is `None`, the timeout will never trigger.
- If `when < loop.time()`, the timeout will trigger on the next
iteration of the event loop.
"""
self._state = _State.CREATED
self._timeout_handler: Optional[events.TimerHandle] = None
self._task: Optional[tasks.Task] = None
self._when = when
# ...
def reschedule(self, when: Optional[float]) -> None:
"""Reschedule the timeout."""
assert self._state is not _State.CREATED
if self._state is not _State.ENTERED:
raise RuntimeError(
f"Cannot change state of {self._state.value} Timeout",
)
self._when = when
if self._timeout_handler is not None:
self._timeout_handler.cancel()
if when is None:
self._timeout_handler = None
else:
loop = events.get_running_loop()
if when <= loop.time():
self._timeout_handler = loop.call_soon(self._on_timeout)
else:
self._timeout_handler = loop.call_at(when, self._on_timeout)
async def __aenter__(self) -> "Timeout":
self._state = _State.ENTERED
self._task = tasks.current_task()
self._cancelling = self._task.cancelling()
if self._task is None:
raise RuntimeError("Timeout should be used inside a task")
self.reschedule(self._when)
return self
async def __aexit__(
self,
exc_type: Optional[Type[BaseException]],
exc_val: Optional[BaseException],
exc_tb: Optional[TracebackType],
) -> Optional[bool]:
assert self._state in (_State.ENTERED, _State.EXPIRING)
if self._timeout_handler is not None:
self._timeout_handler.cancel()
self._timeout_handler = None
if self._state is _State.EXPIRING:
self._state = _State.EXPIRED
if self._task.uncancel() <= self._cancelling and exc_type is exceptions.CancelledError:
# Since there are no new cancel requests, we're
# handling this.
raise TimeoutError from exc_val
elif self._state is _State.ENTERED:
self._state = _State.EXITED
return None
def _on_timeout(self) -> None:
assert self._state is _State.ENTERED
self._task.cancel()
self._state = _State.EXPIRING
# drop the reference early
self._timeout_handler = None
Timeoutclass
async with asyncio.timeout(self.stream_timeout): # __aenter__ Call
async for chunk in super()._astream(*args, **kwargs): # Internal Task Execution
yield chunk
# __aexit__ Call
The Timeout class is an asynchronous context manager that implements __aenter__ and __aexit__, operating according to the flow described above.
Examining its internal logic, upon entering the async with block, self._task is assigned to the currently executing task. Subsequently, reschedule method is called to check whether the execution time within the context has exceeded the timeout period. If the timeout is exceeded, the event loop is instructed to call _on_timeout method as the next operation.
In the _on_timeout method, it cancels the pre-assigned self._task and changes self._state to EXPIRING. Since the ongoing task is canceled, an exceptions.CancelledError is triggered, causing an immediate exit from the async with block. At this point, __aexit__ is called, which wraps the CancelledError and raises it as a TimeoutError.
Calling astream from the ChatModel Interface
When astream method is called directly from the ChatModel interface, a single task (Task-1) is responsible for returning the response chunks generated by the LLM.
In this scenario, Task-1 directly iterates through the entire async generator. Consequently, if the execution time exceeds the timeout duration, the iteration of the async generator is immediately halted. In other words, the timeout works as intended, applying to the total response generation time even in an SSE (Server-Sent Events) context.
<Task pending name='Task-1' coro=<main() running at ***\test.py:22> cb=[_run_until_complete_cb() at ***\Python\Python311\Lib\asyncio\base_events.py:181]>
self._taskofTimeoutinstance
Calling astream from the Runnable Interface
When the Runnable interface (commonly referred to as a “chain” in LangChain) calls astream, it creates and assigns a separate Task for each individual response chunk.
class Runnable(ABC, Generic[Input, Output]):
# ...
async def _atransform_stream_with_config(
self,
inputs: AsyncIterator[Input],
transformer: Callable[[AsyncIterator[Input]], AsyncIterator[Output]]
| Callable[
[AsyncIterator[Input], AsyncCallbackManagerForChainRun],
AsyncIterator[Output],
]
| Callable[
[AsyncIterator[Input], AsyncCallbackManagerForChainRun, RunnableConfig],
AsyncIterator[Output],
],
config: RunnableConfig | None,
run_type: str | None = None,
**kwargs: Any | None,
) -> AsyncIterator[Output]:
"""Transform a stream with config.
Helper method to transform an Async `Iterator` of `Input` values into an
Async `Iterator` of `Output` values, with callbacks.
Use this to implement `astream` or `atransform` in `Runnable` subclasses.
"""
# ...
try:
while True:
chunk = await coro_with_context(anext(iterator), context) # new task is created to process each individual chunk.
yield chunk
if final_output_supported:
if final_output is None:
final_output = chunk
else:
try:
final_output = final_output + chunk
except TypeError:
final_output = chunk
final_output_supported = False
else:
final_output = chunk
except StopAsyncIteration:
pass
# ...
base.py
This means that the self._task assigned to the Timeout instance is only tied to the specific Task responsible for waiting for the first response chunk, rather than the entire stream of response chunks.
<Task pending name='Task-2' coro=<<async_generator_asend without __name__>()> cb=[Task.task_wakeup()]>
self._taskofTimeoutinstance
In other words, if a timeout occurs before Task-2 (which waits for the first response chunk) is completed, _on_timeout correctly calls self._task.cancel() on the currently executing Task-2 and accurately triggers exceptions.CancelledError. Consequently, a TimeoutError is successfully raised.
However, in a typical scenario, each chunk arrives very quickly. This means Task-2, which self._task points to, completes its work almost immediately. By the time the actual timeout occurs, the task currently in execution is Task-N.
Since the active task is constantly changing, the Timeout instance cannot terminate the specific task currently running. As a result, the LLM on the GPU server continues to generate response chunks even after the timeout period has passed, continuing to occupy both GPU and CPU resources.
Modified Method: Calculating Elapsed Time for Each Task
class ChatVllm(ChatOpenAI):
stream_timeout: float | None = None
def __init__(self, *args, **kwargs):
if "api_key" not in kwargs:
kwargs["api_key"] = SecretStr("vllm-only-base-model")
super().__init__(*args, **kwargs)
self.stream_timeout = kwargs.get("timeout", None)
async def _astream(
self, *args: Any, **kwargs: Any
) -> AsyncIterator[ChatGenerationChunk]:
if self.stream_timeout is None:
async for chunk in super()._astream(*args, **kwargs):
yield chunk
else:
start_time = time.monotonic()
async for chunk in super()._astream(*args, **kwargs):
elapsed = time.monotonic() - start_time
if elapsed > self.stream_timeout:
raise asyncio.TimeoutError(
f"Stream timeout after {elapsed:.2f} seconds"
)
yield chunk
chat_vllm.py
The timeout was implemented by having each Task calculate its own execution time. Each Task references a start_time preserved within the _astream async generator’s frame to calculate the cumulative time spent generating the response for every chunk. If the time taken to generate the N-th response in Task-N exceeds the timeout duration, it stops generating further responses and raises a TimeoutError.
Because the error occurs precisely within the currently executing Task-N, the task creation loop in the Runnable’s _atransform_stream_with_config is halted. Consequently, this successfully stops the LLM on the GPU server from generating any further response chunks.
Version Info
- python 3.11.4
- langchain 1.0.8
- langchain-openai 0.3.34